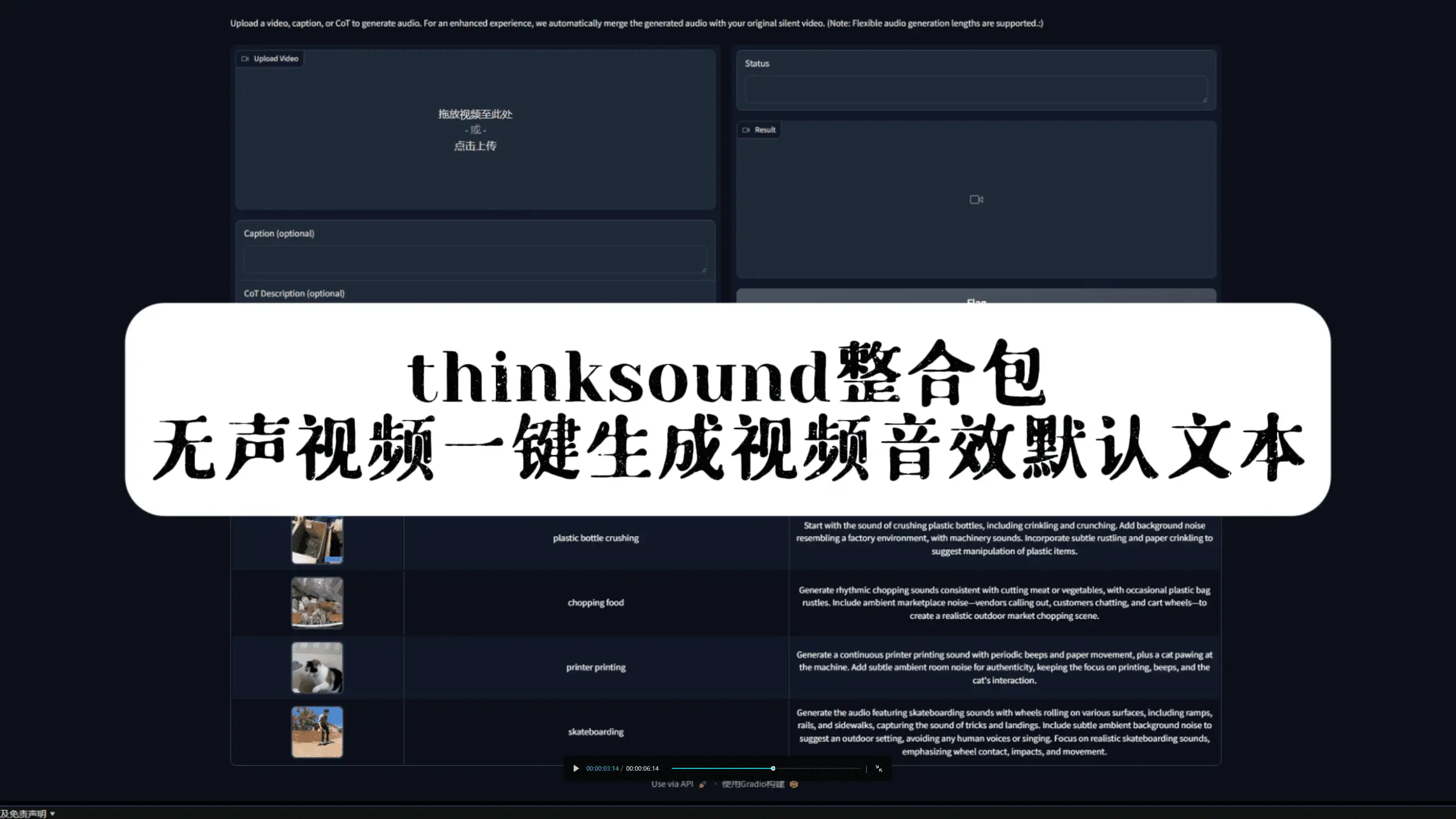

ThinkSound是什么?
ThinkSound是阿里巴巴通义实验室推出的全球首款音频生成模型。它采用先进的链式推理(Chain-of-Thought,CoT)技术,能够深入分析视频画面的场景、动作与情感,进而生成与之高度匹配的音效。无论是自然风声、城市喧嚣,还是角色对话与物体碰撞音,ThinkSound都能实现音画高保真同步,效果逼真自然,堪称“专业AI音效师” 。
优化版整合包下载 包含独家教程
测试效果如下
核心技术架构
-
多模态理解与推理引擎
ThinkSound基于多模态大语言模型(MLLM),实现“思维链”式推理(CoT),首先多层次分析视频帧,识别场景元素(如物体、环境、人物交互)、动作动态和情感语境,在此基础上进行语义推理。模型实现对场景语义的结构化理解,细化到具体声源(如水流声、鸟鸣、车辆鸣笛),最后依据用户需求和场景特征进行推断。 -
结构化推理机制
引入CoT技术,模型在生成之前形成渐进式的“推理链”,逐步由总体场景理解过渡到具体声源细节,从而提高音效的场景一致性和还原度。此机制的关键在于两个环节:一是全局理解和场景归纳,二是局部细节推理,确保生成音频在时间、空间上的高同步性。 -
统一高保真音频生成模型
ThinkSound采用端到端的统一音频生成体系,在深度学习基础上训练极高多样性的声纹数据库(AudioCoT),模型输出的声音具有真实感、空间感和上下文关联性。通过多样化的样本训练,模型能够根据推理的场景内容,准确合成环境噪声、角色对话、物理声效等,为复杂场景提供可拓展的音频解决方案。多模态数据集——AudioCoT
为支撑复杂推理需求,通义团队构建了涵盖2531.8小时多源多场景音频的AudioCoT数据集。该数据集汇聚了VGGSound、AudioSet、AudioCaps、Freesound等多个公开资源,经过严格筛选和多阶段质量把控,确保数据的高质量、多样性和标注精细。特别设计的对象级和指令级标注,为模型提供了结构化的指令和对应场景音效的映射关系,满足交互式编辑和自定义生成的高要求。
软件运行电脑配置
为了确保您获得最佳体验,请仔细核对以下电脑配置要求!
📋 核心配置要求:
- 操作系统 (OS): Windows 10/11 64位系统 ✅
- 内存 (RAM): 推荐 16GB及以上 🧠 (保障软件流畅运行的关键!)
- 显卡 (GPU): 英伟达 (NVIDIA) 显卡,显存至少8GB及以上 🎮
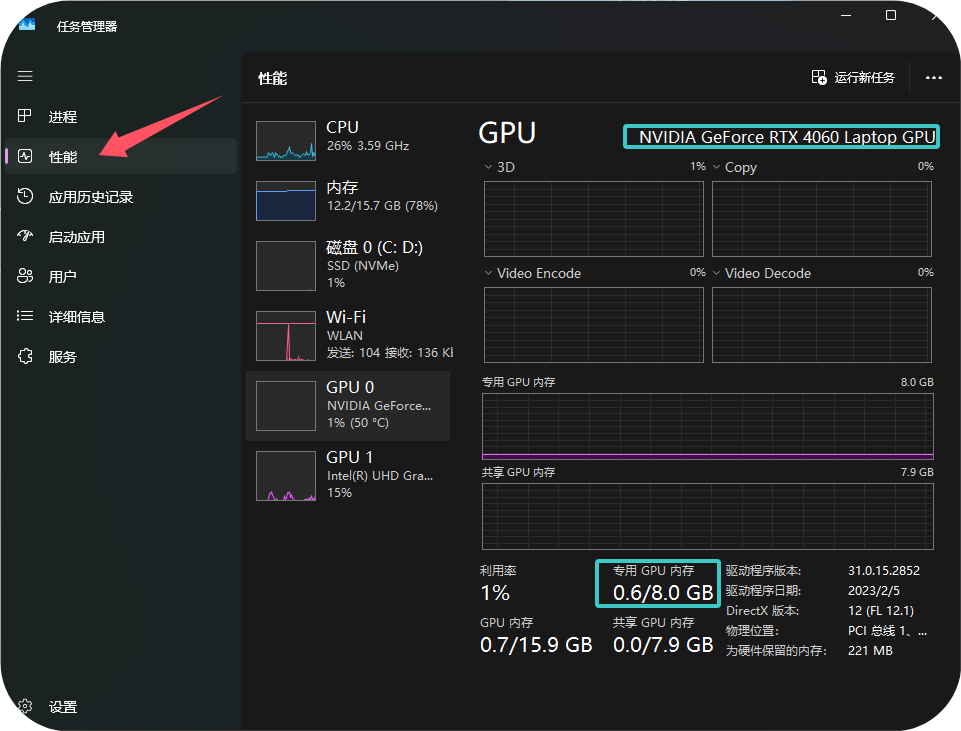
🔍 如何快速查看显卡信息?
- 打开 任务管理器 👨💻 (可以通过Ctrl+Shift+Esc快捷键打开)
- 切换到 “性能” 选项卡 📈
- 点击左侧的 “GPU” 选项 💡
- 右上角即显示您的 显卡型号,下方则能看到 显存大小 !
-

















暂无评论内容