

简介
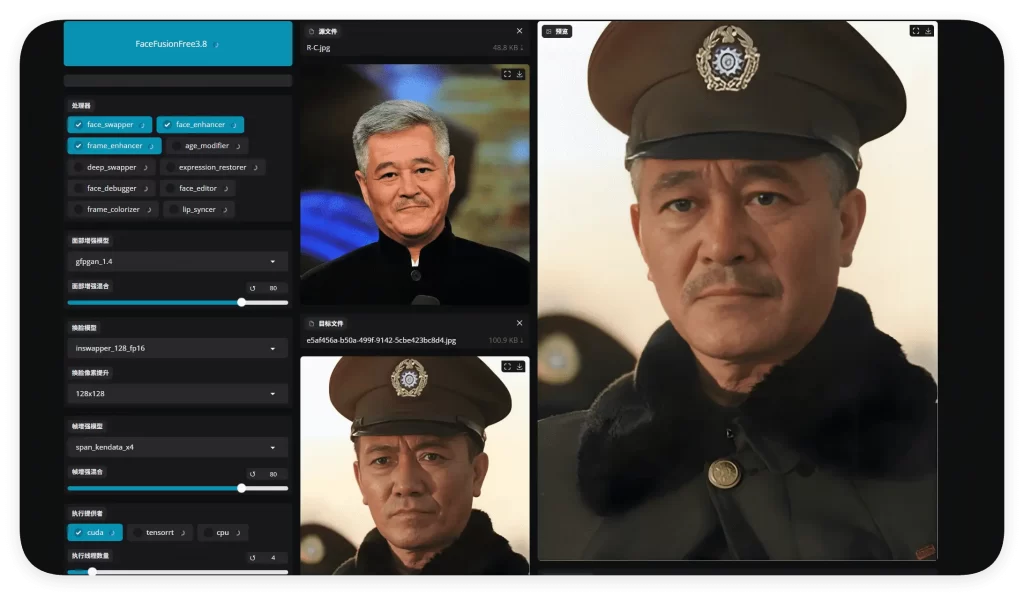
一个使用简单但功能强大的工作流,工作流匹配教程在评论区,目前是beta版本,因为太多人找我要工作流,所以先发出来,会持续优化效果,主要是提升声音的克隆和画面人物的贴合程度。目前的工作流大家只需上传 2 个原视频和 1 段用于复现声音的音频就可以了,后续会开源专属这个工作流的comfyUI整合包,因为使用的节点插件都很难安装。
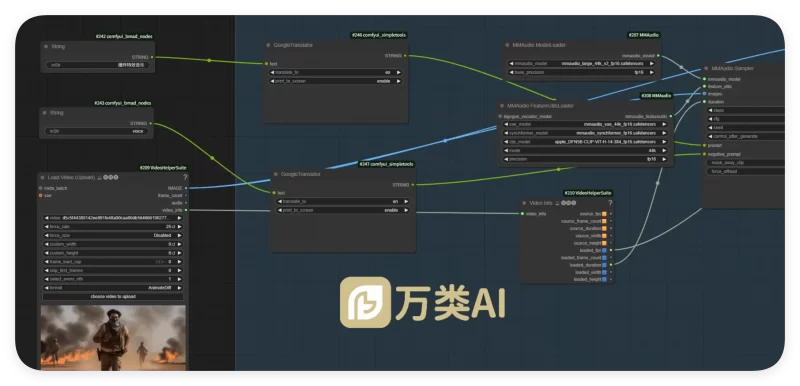
工作流节点截图
附件文件一览

模型
vae-ft-mse-840000-ema-pruned.safetensors👉
dw-ll_ucoco_384_bs5.torchscript.pt👉
内置节点
AudioPlay
ChatTTS_
GetNode
LoadAndCombinedAudio_
LoadWhisperModel
Note
OpenVoiceClone
Qwen2_ModelLoader_Zho
Qwen2_Zho
SetNode
UNETLoader_MuseTalk
muse_talk_sampler
vhs_audio_to_audio_tensor
whisper_to_features
自定义节点
ComfyUI
– EmptyImage
– ImageToMask
– MaskToImage
– ImageCompositeMasked
– VAELoader
– PreviewImage
ComfyUI Essentials
– ImageResize+
ComfyUI Nodes for Inference.Core
– PixelPerfectResolution
– DWPreprocessor
ComfyUI Whisper
– Apply Whisper
ComfyUI-VideoHelperSuite
– VHS_VideoCombine
– VHS_LoadVideo
– VHS_LoadAudio
KJNodes for ComfyUI
– GrowMaskWithBlur
– BatchCropFromMask
– BatchUncrop
pythongosssss/ComfyUI-Custom-Scripts
– ShowText|pysssss
Save Image with Generation Metadata
– String Literal
2.某些节点可能过于老旧或被弃用,建议把同类节点升级或尽量使用新日期的 工作流节点。
由于本网站资源是搜集整理而成,版权均归原作者所有。网站内所有资源仅供学习交流之用,请勿用作商业用途,并请于下载后24小时内删除,如果喜欢,请支持正版,谢谢。






















暂无评论内容