
简介
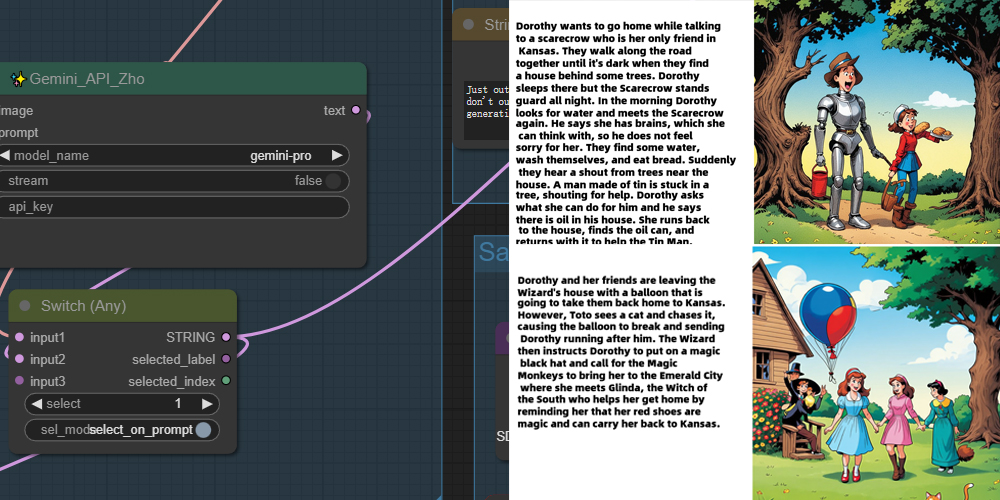
此工作流可以阅读英文PDF文件进行OCR并汇总文档内容,输出为文本,将文本转换为图像生成提示。然后使用SD3生成图像并与文本结合,输出1920×1080图像(看起来像演示文稿)。
摘要使用 Ollama,OCR功能使用 Florence2。此工作流可以从 arXiv 读取 PDF,对其进行总结,并生成伴随摘要的插图。然而,此工作流并不适合用作学术论文,因为此类论文中的图像(如另一张图像中的 SD3 论文)是由 SD3 随机生成的。但如果是小说或故事类的文本,相信效果会不错。
工作流节点截图

附件文件一览

模型
Checkpoints
sd3_medium_incl_clips_t5xxlfp8.safetensors👉
内置节点
DownloadAndLoadFlorence2Model
EmptySD3LatentImage
Fast Groups Bypasser (rgthree)
Florence2Run
ImageConcatMulti
LayerUtility: SD3NegativeConditioning
PDFToImage
自定义节点
Comfyroll Studio
– CR Text Concatenate
ComfyUI
– CLIPTextEncode
– CheckpointLoaderSimple
– PreviewImage
– SaveImage
ComfyUI Impact Pack
– ImpactSwitch
ComfyUI Layer Style
– LayerUtility: ColorImage V2
– LayerUtility: SimpleTextImage
– LayerStyle: DropShadow
ComfyUI Ollama
– OllamaGenerate
ComfyUI-Gemini
– Gemini_API_Zho
Efficiency Nodes for ComfyUI Version 2.0+
– KSampler (Efficient)
Save Image with Generation Metadata
– String Literal
WAS Node Suite
– Text List to Text
– Text List
2.某些节点可能过于老旧或被弃用,建议把同类节点升级或尽量使用新日期的 工作流节点。
由于本网站资源是搜集整理而成,版权均归原作者所有。网站内所有资源仅供学习交流之用,请勿用作商业用途,并请于下载后24小时内删除,如果喜欢,请支持正版,谢谢。






















暂无评论内容