

作者:MiaoshouAI
简介
随着FLUX模型的发布, LLM的使用变得更加普遍,因为该模型能够通过T5和CLIP_L模型的结合来理解自然语言。然而,大多数LLMs都需要较大的 VRAM,并且其返回的结果并未针对图像提示进行优化。结合PromptGen v1.5,使用 PromptGen 时,大大提高了捕捉图像细节的能力和准确性。您不会收到诸如“此图片是关于…”之类的烦人文本。
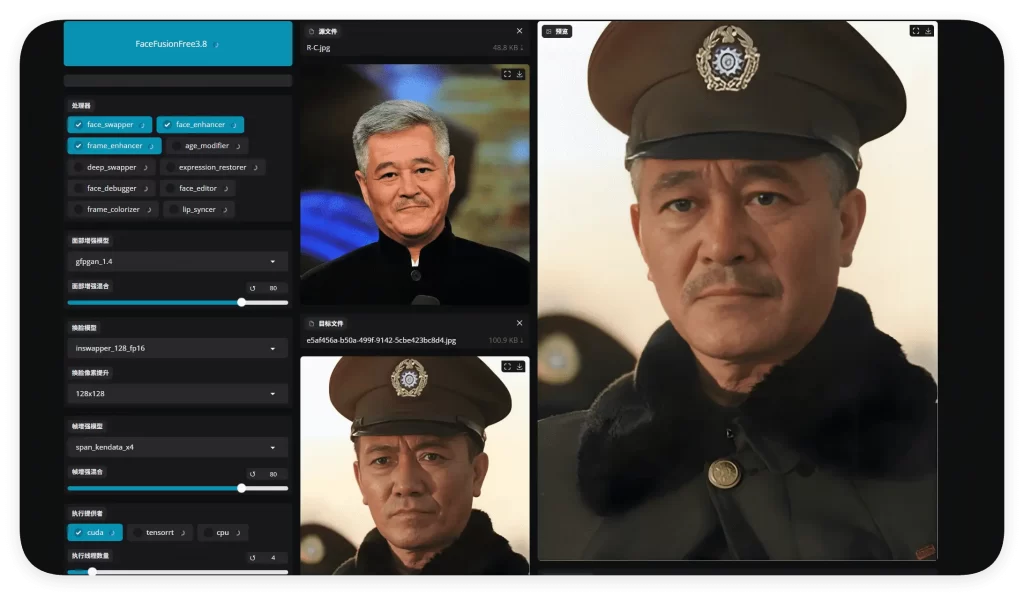
工作流节点截图

附件文件一览

模型
Florence-2-base-PromptGen-v1.5.safetensors👉
LoRAs
anime_v1_000019000.safetensors👉
内置节点
Miaoshouai_Flux_CLIPTextEncode
Miaoshouai_Tagger
Note
Switch string [Crystools]
自定义节点
AnimateDiff
– ImageSizeAndBatchSize
ComfyUI
– KSampler
– VAEDecode
– SaveImage
– VAELoader
– EmptyLatentImage
– VAEEncode
– UNETLoader
– DualCLIPLoader
– LoraLoader
– LoadImage
ComfyUI-Logic
– If ANY execute A else B
– Float
ComfyUI-string-util
– string_util_StrEqual
pythongosssss/ComfyUI-Custom-Scripts
– ShowText|pysssss
Various ComfyUI Nodes by Type
– JWImageResizeByShorterSide
常见问题
工作流报错?
工作流报错包括缺少节点、模型等。缺少模型可按工作流内模型名称进行站内搜索。
工作流缺少节点?
1.不同的ComfyUI工作流会涉及不同的扩展节点,最快解决方法是下载扩展管理器ComfyUI-Manager(https://github.com/ltdrdata/ComfyUI-Manager)来自动补全缺失节点。
2.某些节点可能过于老旧或被弃用,建议把同类节点升级或尽量使用新日期的 工作流节点。
2.某些节点可能过于老旧或被弃用,建议把同类节点升级或尽量使用新日期的 工作流节点。
工作流模型和推荐模型不一样?
有些工作流使用的模型与文章推荐的模型会有所不同,这是因为模型版本一直在更新,我们尽可能选择不改变效果的范围内给您推荐较新版本的模型,所以会导致有些模型的名称与工作流内的模型名称不相同,但不影响使用,在使用的过程中可以留意一下就好。
模型下载后要怎么安装?
一般模型分为大模型CheckPoint和风格模型LoRA、VAE或CLIP等类型,多数情况下,它们都应分别放在ComfyUImodels目录下对应类型的文件夹内即可,而有些基础模型则要放在其扩展名称的models文件夹内。基础模型种类繁多且,他们的安装方法一般在其官方链接中有详细说明。
模型下载后可以修改文件名吗?
重命名不会影响该模型的功能,但会导致 工作流节点找不到原来的模型文件。虽然可以手动选择,但不建议这么做!因为模型的种类和版本成千上万,名称相似的也数量不少,一旦随意更改模型原名称,很可能会造成众多模型文件过于混乱对不上号的可能。
/workflow-auto-flux-image.html,转载请注明出处。
由于本网站资源是搜集整理而成,版权均归原作者所有。网站内所有资源仅供学习交流之用,请勿用作商业用途,并请于下载后24小时内删除,如果喜欢,请支持正版,谢谢。
由于本网站资源是搜集整理而成,版权均归原作者所有。网站内所有资源仅供学习交流之用,请勿用作商业用途,并请于下载后24小时内删除,如果喜欢,请支持正版,谢谢。
© 版权声明
模型版权归作者所有,仅供娱乐,请于下载后24小时内删除。侵权联系 mxgf.cc@foxmail.com
THE END























暂无评论内容